Warning! Your devicePixelRatio is not 1 and you have JavaScript disabled!
(Or if this message is not in a red box, your browser doesn't even support basic CSS and you can probably safely ignore this warning.
You'll encounter way more suboptimal things in that case...)
Since HTML is as braindead as it can get, pixel graphics might look off without javashit workarounds.
Try to get a non-HiDPI screen or enable javashit for best results.
Loudness normalization with FFmpeg
Created: 1725908832 (2024-09-09T19:07:12Z), Updated: 1729543407 (2024-10-21T20:43:27Z), 3458 words, ~15 minutes
Tags: linux, tech, rant, meta, blog update
This post is part of series blog update: 2023, 2024, 2025, 2026
AKA 2024 updates
I was writing a blogpost on NFS2 (to be published soon™), when I made the mistake of opening one of the video files in Audacity with show clipping on—and oh my gosh, it was all red.
Even the original recording was heavily clipped, and this prompted me dig around—and so a multi-day journey began.
First thing I did was switch obs-studio to record float samples instead if S16, so at least in my input videos samples won't be clipped. I didn't redo the old recordings, they're still broken and there's no fixing them, but at least new ones won't have this problem. Well, as long as the game can output float samples, it won't help if the game uses S16 internally. Or if I run it in DOSBox, which can only record what a 90s soundcard could do. And of course, this in only half the problem, when I encode the videos to the blog, I have to keep samples under 1, because most lossy codecs will clip the samples to [-1, 1]. And checking some of the existing videos on the blog, I quickly realized that their loudness was all over the place. They should be normalized. So my journey with FFmpeg began.
First I found the replaygain filter, which calculates a ReplayGain tag and adds it to the file, but it's more for tagging than doing the actual normalization.
And while any not seriously broken music player understands ReplayGain tags, the same can't be said of video players.
So I must normalize the audio streams, which shouldn't be a big deal, as I have to re-encode audio tracks anyway.
Some search later I landed upon the loudnorm filter, which unlike the replaygain filter, calculates loudness according to EBU R 128 instead of simply finding peak loudness, so it should be way better, and also supports normalizing in one filter.
Cool! ...
That's what I thought.
But of course, this is FFmpeg.
It wouldn't be FFmpeg if something simply would work as advertised, and it wouldn't be filled with fucking landmines everywhere.
Loudness normalization in nutshell and terminology#
But before I start rambling about FFmpeg, what is loudness normalization anyway, what do we want to achieve?
EBU R 128 includes a method to calculate loudness of an audio stream that attempts to take human perception into account.
The result of this is usually reported in LUFS, where LU stands for Loudness Unit (and has the same unit as dB), and FS for Full Scale.
0 LUFS corresponds to 0 dB on the absolute digital scale (i.
Another common element is TP, short for True Peak, which is the peak of the signal. Here true refers to that you have to take the real, reconstructed signal, not just the sampled points. In practice, this is calculated by upsampling the signal to a high frequency (192 kHz in FFmpeg's case), and finding the maximum of that signal. Measured in dBTP, and don't ask how it's different from dB...
There's also LRA, short for Loudness RAnge, which describes the loudness variation of the input, but I didn't find any good info on what is this exactly. (And I couldn't be assed to read the specification). Probably not that important.
So what's the goal here?
To make sure all audio tracks have roughly the same loudness.
So if you read one post on my site, see a video, then switch to a different post, the video there won't be suddenly too quiet or loud.
And of course we have to do it in a way that we don't overshoot the maximum value our digital equipment can produce (i.
There are two big competing standards to note here, EBU R 128 specifies a -23 LUFS loudness and a -1 dBTP peak (less if you apply a lossy codec).
This is supposedly mandatory if you want to run a TV channel in the EU, but there's no such requirements for internet sites, and frankly, normalizing to -23 LUFS results in a pretty quiet audio in today's loudness war's world.
The second standard here is AES's streaming recommendations, which recommends a -16 LUFS loudness and -1 dBTP peak, which is a much more reasonable choice these days.
Some sites even go to higher loudness values, but -16 LUFS should be OK for me.
I'm not trying to deafen you.
Update 2024-10-21: that's what I thought.
Then I realized I made a few mistakes.
First, don't use -ac 2 to make mono sound, ffmpeg will convert stereo to mono at the end of the filtergraph, but you want to do it before the loudnorm filter (solution: use aresample=ochl=mono to get mono audio).
Also loudnorm has a dual_mono flag which probably should be set (of course, ffmpeg being ffmpeg every flag has a wrong default value), so it will have a correct loudness if you play the mono sound on stereo speakers.
Then while making videos for my upcoming NFS3 article, after I figured out how to make NFS3 not output ridiculously compressed audio, the dynamic range of -16 LUFS became too small (and also with the fixed loudness calculation, mono audio files also started hitting TP).
So right now I'm reencoding videos to -18 LUFS, which is a less established standard... but -23 LUFS is way too quiet.
End update.
Two pass loudnorm#
If you read the man page, you quickly figure out that loudnorm has actually two modes, dynamic and linear normalization modes.
Dynamic means that it dynamically changes the amplification, while linear means it'll just apply a constant amplification to the whole track.
Now, the dynamic mode has a tendency to destroy songs.
It only needs a single pass, so if you have a live stream where you don't care too much about the audio quality (like a podcast), it might be a good choice, otherwise forget about it.
So linear mode I need.
Unfortunately it's a two pass algorithm, at the first pass it calculates the loudness of the audio, and in the second pass it uses the calculated loudness from the first pass to adjust the volume.
Sounds simple?
WRONG.
You have the print_format option which you should set to summary or json to receive the measurements somehow, then you have to feed them into the measured_* params on the second invocation.
Where does this filter print this result?
To the stderr, intermingled with all other log messages and ffmpeg status messages.
Where's the option to redirect it to a file or any other less retarded place?
Nowhere.
And how does this output look like, by the way?
Something like this:
[Parsed_loudnorm_0 @ 0x5601a72fd3c0]
{
"input_i" : "-4.66",
"input_tp" : "0.63",
"input_lra" : "3.40",
"input_thresh" : "-14.81",
"output_i" : "-23.87",
"output_tp" : "-13.35",
"output_lra" : "3.40",
"output_thresh" : "-33.93",
"normalization_type" : "dynamic",
"target_offset" : "-0.13"
}
(Here I refers to integrated LU, momentary LU integrated over the input).
Yes, pretty printed JSON, so I can't process the output by line, and also the numbers are stored as strings.
That green color on the first line is not a syntax highlight, the line starts with the ANSI escape sequence of "\e[48;5;0m\e[38;5;155m[" and ends with "\[0m".
Yes, 256-colors!
So I have to parse this fragile mess?
I tried to mess around with ffmpeg's -loglevel parameter, maybe I can set it to something where it won't print other unnecessary garbage, but it is printed with info severity, so you need at least -loglevel info, but that already prints a lot of crap.
This can't be this complicated, I went searching the net, and I found the author's blog, where he has the audacity to say:
Of course, dual-pass normalization can be easily scripted.
Easily scripted?
What is this madman talking about?
/me proceeds to check the code.
The gist of the parsing is this:
stats = JSON.parse(stderr.read.lines[-12, 12].join)
(For people not speaking Ruby, it just takes the last 12 lines of stderr output and parses it as JSON).
What!?
Are you fucking stupid or what?
Where is in the goddamn documentation that the JSON will be exactly 12 lines long?!
What if there is a new version and it adds a new filed?
Your fucking script will break.
But wait, we don't have to go that far.
Let's suppose something is acting up, so you add -loglevel debug to the parameters to debug... and BAM!
It will print some crap after the JSON, so your easily scripted script breaks.
Yes, it's easily scriptable if you don't care about breaking your script from the slightest change in FFmpeg.
If you want something robust, I guess you have to train some LLM model on random outputs of a high variety of programs trying to find a JSON corresponding to a loudnorm filter, so it has some chance of working even if ffmpeg output changes a bit.
Yeah, spending months to research AI LLM models and train a multi gigabyte neural network just to extract something from the output of the program in a way that it has a chance of working after an update (but also has a chance of breaking randomly) is considered easily scriptable.
Why don't you do a favor to the world, and impale yourself on a stick you fucking nigger gorilla idiot?!
...
Some ranting later, I took the bullet and wrote some code that I considered less fragile than the brainlet author's retarded [-12, 12]... just so it also broke when I ran ffmpeg with -loglevel debug.
Anyway, after I finally parsed the output, forwarded the parameters to the second invocation as in the example, ran it on a test file, everything seemed to be in working order.
Oh boy, how wrong I was.
While searching, I stumbled upon this blogpost(?), which mentioned needing a filter to convert back audio back to 48 kHz, even in the second pass.
But according to the man page, upsampling to 192 kHz only happens in dynamic mode.
Was that a quirk of an older version?
Later finding a not-stackoverflow post enlightened me.
Let's re-read the documentation of the linear parameter (emphasis mine):
Normalize by linearly scaling the source audio.
measured_I,measured_LRA,measured_TP, andmeasured_threshmust all be specified. Target LRA shouldn't be lower than source LRA and the change in integrated loudness shouldn't result in a true peak which exceeds the target TP. If any of these conditions aren't met, normalization mode will revert todynamic. Options aretrueorfalse. Default istrue.
Let's re-re-read the bold sentence, and let that sink in.
If any of those loosely defined conditions don't hold, loudnorm will switch back to dynamic mode, destroying your soundtrack.
But.... you'll at least get a warning in this case, right?—you may ask.
NO!
NO FUCKING WAY!
NOT EVEN WITH -loglevel debug!
It just silently destroys your audio, showing a middle finger behind the scenes, laughing her ass off.
This is FFmpeg, what did you expect?
To not being completely useless for once?
Hahaha!
The only way to detect when this case happens is to have print_format in the second pass too and check if it has normalization_mode: linear.
If not, it fucked up your file.
An alternate way to detect is that if the filter suddenly upsamples audio to 192 kHz in the second pass, it fucked up the audio.
So the poor guy I linked above fucked up his audio files.
At this point I was already looking at the source code (and let me interject there for a moment, this is why I like open-source software, at least I can view the code and see what's going on because documentation is always lacking.
And before you say that's what I get for using free software, proprietary expensive software aren't better either, but there I don't even have the source code, so figuring out issues is even harder.
Stay tuned for an Adobe Premiere rant later), what are exact conditions needed to trigger linear mode?
Here's the relevant part from af_loudnorm.c:
if (s->linear) {
double offset, offset_tp;
offset = s->target_i - s->measured_i;
offset_tp = s->measured_tp + offset;
if (s->measured_tp != 99 && s->measured_thresh != -70 && s->measured_lra != 0 && s->measured_i != 0) {
if ((offset_tp <= s->target_tp) && (s->measured_lra <= s->target_lra)) {
s->frame_type = LINEAR_MODE;
s->offset = offset;
}
}
}
linearmust be set totrue(doh).- None of the
measured_*parameters can be set to the default value. Notice how the man page says "must all be specified." Wrong! They must be specified AND not set to the default value. I guess if your input is normalized to 0 LUFS, you're out of luck. measured_lra <= target_lra. This is the "Target LRA shouldn't be lower than source LRA" part.measured_tp + target_i - measured_i <= target_tp. This is the "the change in integrated loudness shouldn't result in a true peak which exceeds the target TP" part.
Let's mull over the last requirement.
What this filter does in linear mode is that it adjusts the volume of all samples by offset = target_i - measured_i decibels.
(Everything in the above code is in dB).
So measured_tp + target_i - measured_i tells us the new TP in the output if we apply that volume adjustment.
And of course, that can't go over our goal.
Armed with this knowledge, how can we prevent the catastrophe?
One way is to keep the print_format on the second pass, parse the output, and if it has a dynamic mode, print an error message along the lines of, "Sorry, I fucked up your output, do something with the soundtrack and try again fuckface, hahaha!"
The second option is to implement all these checks in the script calling ffmpeg, and do something when they fail.
Which brings me to the second topic, something what I already hinted at, what is a linear loudnorm?
The answer is: volume=(target_i - measured_i)dB.
Yes.
You only need the measured_i parameter.
All those other measured_* parameters are just there to fuck with you, to destroy your audio silently.
First I wanted to impale the author on a stick, but now I think he'd need the most painful way to die.
AAAAARGGH!!!
loudnorm in practice#
So, now what to do?
Since a linear loudnorm is just a fancy way to call a volume filter, I decided to do that very complicated mathematical computation of subtracting two numbers in my video generator script, and just call FFmpeg's volume filter directly.
At least that won't quietly change to dynamic normalization, even if a later FFmpeg version changes the logic in loudnorm, or due to floating point rounding errors, my script says that some numbers are just valid, but the C code rounds a bit differently and says it's invalid.
Update 2024-10-21: actually, I no longer use the loudnorm filter.
There's an ebur128 filter which is faster, has an output that at least seems like machine readable (but have fun figuring it out from the documentation), and will never change your audio stream (but I just pipe it to /dev/null because normalization is 2-pass).
It also calculates a few more interesting values, like momentary I values, but I'm not using them.
What you want is something like this:
-af ebur128=metadata=1:framelog=quiet:peak=true:dualmono=true,ametadata=mode=print:file=$FILENAME -f null -
and replace $FILENAME with the name of the file where you want the output.
(Or you can use simply peak=sample if you upsample the audio before to 192 kHz...
It also has parameters like input which according to the documentation is "Read-only exported value for measured integrated loudness, in LUFS.", which sounds like exactly what I need, except I couldn't find any trace of how to read a parameter of a filter, neither in the man page or on the internet...)
framelog=quiet makes the filter shut up (by default it prints a line with momentary loudness and others every 0.metadata=1 makes the measured values available as metadata, and the ametadata filter will write it to a file.
The file will have a buch of blocks like this:
frame:144 pts:2764800 pts_time:14.4
lavfi.r128.M=-19.189
lavfi.r128.S=-18.453
lavfi.r128.I=-18.656
lavfi.r128.LRA=3.540
lavfi.r128.LRA.low=-24.420
lavfi.r128.LRA.high=-20.880
lavfi.r128.true_peaks_ch0=0.674
lavfi.r128.true_peak=0.674
You need to find the last one (I don't know if you can do it from ffmpeg, I gave up making sense of it and I just parse the output from a Ruby script), and get the value of lavfi.r128.I (expressed in dB) and lavfi.r128.true_peak (expressed sample value).
Yes, they have different units.
20 * log10(peak) will get you decibels for the peak.
It's ffmpeg, don't try to make sense of it.
End update.
What to do with the two other parameters loudnorm has?
LRA is the easier, neither R 128 nor the AES standard has any recommendation on maximum LRA values, so I just ignored it.
(It's not like I can target a specific LRA without completely destroying the dynamics of the input anyway.)
I have no idea where the 7 LU default value and 11 LU in the author's blogpost came from.
But the peak, that will be more problematic.
First I tried to use asoftclip, which I figured would be OK if the sound samples go just over the limit here and there.
(By default it'll clip to 0 dB instead of -1 dB, but that's the lesser problem).
I implemented it, but the first few videos needed no clipping, so everything seemed alright, until I got to Didnapper.
And there everything fell apart.
Didnapper is so badly mixed, that the random sound effects are WAY louder than the background music.
Actually saying that it is mixed is probably an overstatement, just look at the waveform of the sidemission video:
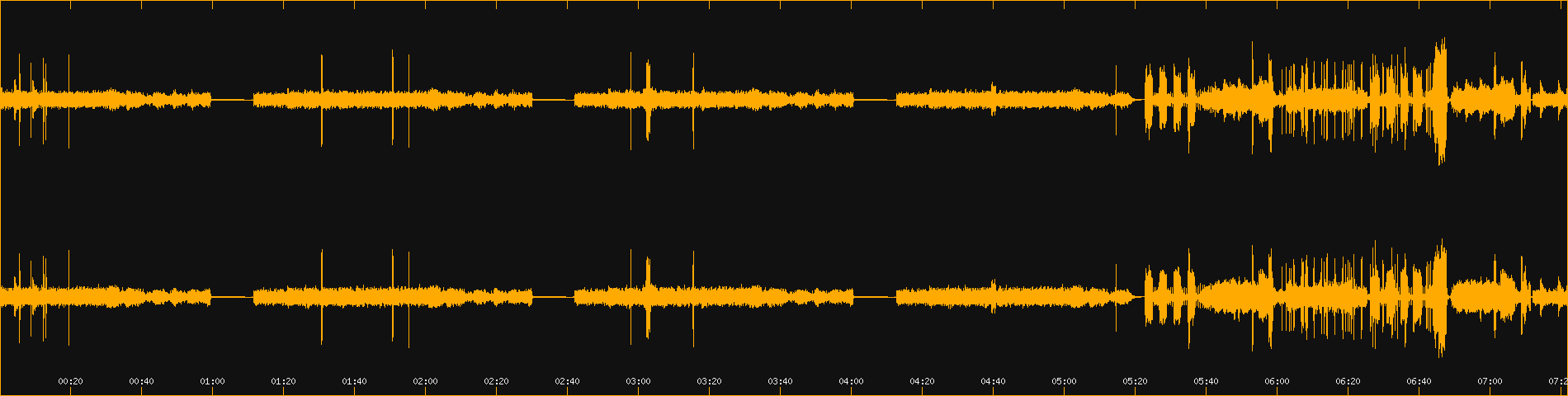
Can you tell me when the background music changes? Also those spikes, yikes! I ended up with 5-6 dBTP values after normalizing. That will sound shit, no matter what kind of soft clipping you use. Well, back to the drawing board.
So second attempt, try to normalize to -16 LUFS, but decrease the volume if we're over -1 dBTP (and complain loudly).
This solved the clipping problem, but now Didnapper videos became really quiet.
Maybe I should fall back to normalizing at -23 LUFS?
But that was really quiet, and even with -16 LUFS target, Didnapper was the only game that required me to increase the volume.
Every other game is so fucking compressed at maximum volume, that it's ridiculous.
After messing around with my options for a long time, in the end I decided to compress the two Didnapper recording with acompressor to get rid of the ridiculous spikes.
Here's some sound processing horror, before-after.
Sorry about that.
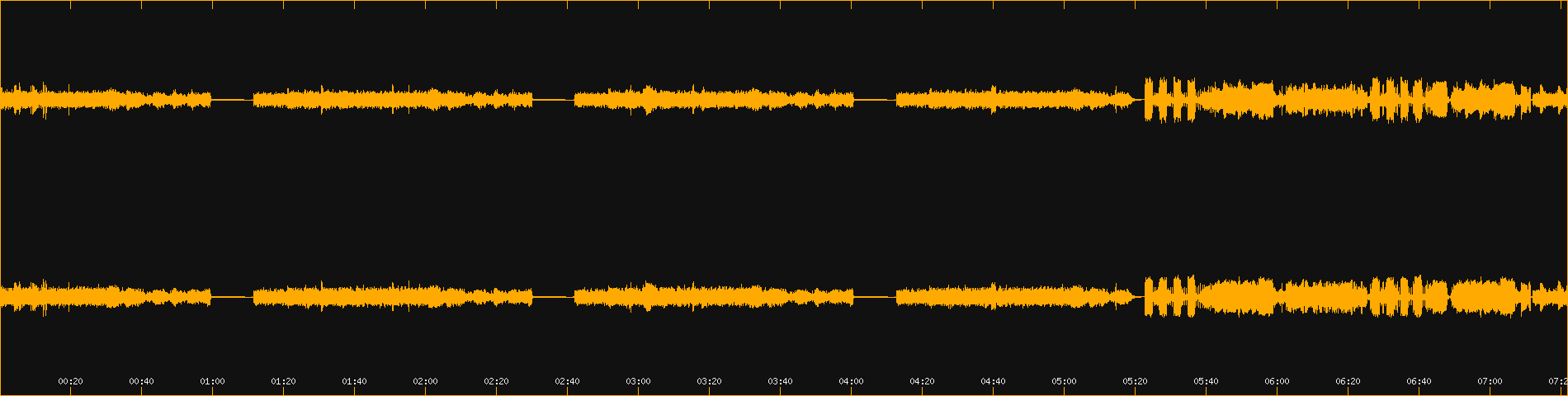
(Update 2024-10-21: using -18 LUFS didn't remove the need to compress Didnapper's sound, I just don't need to compress it that much.)
Random consequences#
Because of the above, I had to re-encode the audio tracks of all videos on the site.
And if I have to touch every video, I might just make some other minor improvements too.
Most videos (where it makes sense) now have a subtle fade-in/
A second change I made was to re-encode every VP9 coded video in a slightly lower quality, and at the same time officially calling it medium quality. It didn't matter too much with 2D games of 640x480 or lower resolution where barely anything changes between frames, but these 60 FPS Full HD Need for Speed videos with a lot of happening between frames, they started to become a bit too big, especially that in the old setup I had high quality, slightly lower quality than high in a different format, and low quality video files. That VP9 files just looked like a wasted duplicate for the few users out there who can't play AV-1 movies. Now at least the quality scale is more even. (It's not perfect, for that I'd have to fine tune CRF values for each video on each quality level, and I'm not gonna do that. VMAF is nice in theory, but it's not a reliable scoring between different videos, and breaks down horribly when fed with non-HD non-real-life-like footage.) And to be honest, most video hosting sites would probably still call high quality what I call medium quality, and I didn't touch AV-1 videos, so high quality is unchanged. (It would be nice if I could host lossless videos, but they're huge).
A third completely unrelated change is that while looking at the upscaled NFS4 intro, I wondered—if there are image upscale AIs, is there any AI that could do something with the 22050 Hz compressed beyond hell audio track? And the answer is yes, meet AudioSR! Well, the result was not as impressive with the 8 kHz samples on the website, so um, whatever.